Bias-Variance Tradeoff#
Before we dive into the concept of bias, let’s briefly recap some theoretical concepts you learned about in the lecture. When we talk about fitting machine learning models, we are referring to the process of estimating a function \(f\) that best represents the relationship between an outcome and a set of labelled data (in supervised learning) or to uncover structural patterns in unlabelled data (in unsupervised learning). While the estimated function \(\hat{f}\) conveys important information about the data from which it was derived (the training data), our primary interest is in using this function to make accurate predictions for future cases in new, unseen data sets.
The fundamental question in statistical learning is how well \(\hat{f}\) will perform on these future data sets, which brings us to the concept of the bias-variance tradeoff. Bias occurs when a model is too simple to capture the underlying complexities of the data, leading to systematic inaccuracies in its predictions. Variance measures how much the model’s predictions fluctuate when trained on different subsets of the data.
Reminder: Types of Errors
The irreducible error is inherent in the data due to noise and factors beyond our control (unmeasured variables).
The reducible error arises from shortcomings in the model and can be further broken down into:
Bias: Introduced when a model makes too simple assumptions about the data (underfitting)
Variance: The sensitivity of the model to small changes in the training data (overfitting)
This closely relates to the example introduced in Recap: Regression Models. Let’s have a another look and simulate some data with an underlying relationship in line with a cubic polynomial function. We can see that a linear regression does not capture the nuance of the cubic relationship in the data, while a 10th order model already overfits quite a lot:
import numpy as np
x = np.linspace(-3, 3, 30)
y = (x**3 + np.random.normal(0, 15, size=x.shape)) / 10
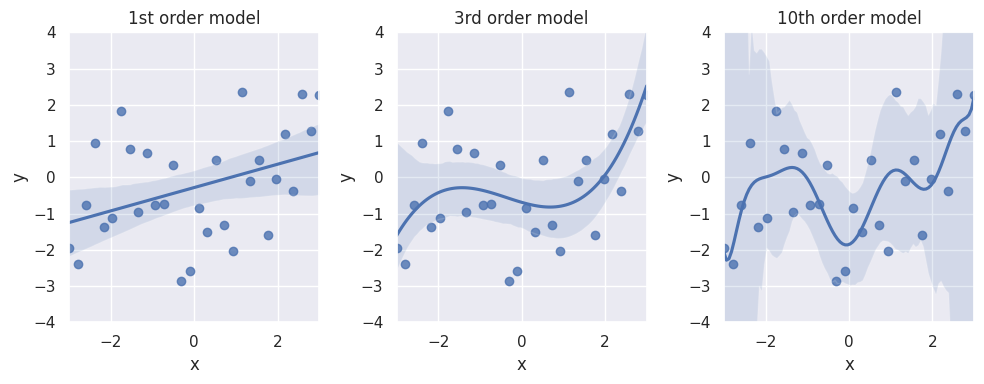
If we look at the mean squared error (MSE), which we here use as a measure for the bias, we can see that it decreases with increasing model flexibility:
Reminder: MSE
\(y_i\) is the actual value for the \(i\)-th observation.
\(\hat{y}_i\) is the predicted value for the \(i\)-th observation.
\(n\) is the total number of observations
The term \(({y_i}−{\hat{y}^i})^2\) represents the squared error for each observation. By averaging these squared errors, the MSE provides a single metric that quantifies how far off the predictions are from the true values.
import statsmodels.api as sm
from sklearn.preprocessing import PolynomialFeatures
# Create data
np.random.seed(42)
x = np.linspace(-3, 3, 30).reshape(-1, 1)
y = (x**3 + np.random.normal(0, 15, size=x.shape)) / 10
# Run the models and calculate the MSE
mse_list = []
model_list = []
degrees = [1, 3, 10]
for degree in degrees:
x_trans = PolynomialFeatures(degree=degree).fit_transform(x)
model = sm.OLS(y, x_trans).fit()
mse = np.mean(model.resid**2)
model_list.append(model)
mse_list.append(mse)
print(f"Degree Train MSE")
print(f"1 {mse_list[0]:.3f}")
print(f"3 {mse_list[1]:.3f}")
print(f"10 {mse_list[2]:.3f}")
Degree Train MSE
1 1.809
3 1.417
10 1.094
However, if we evaluate the same models on new, unseen data, we see that the MSE is now increasing with incrasing order of the polynomial regression model:
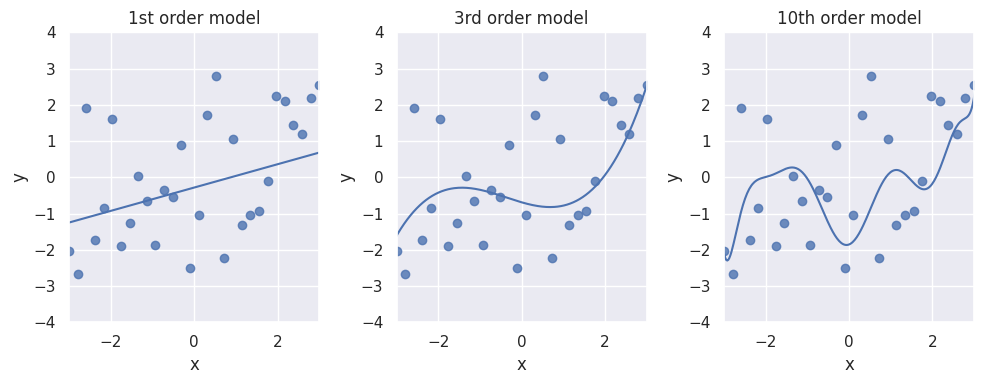
Degree Test MSE
1 2.203
3 2.046
10 2.478
Please compare the previous plots and outputs. What do you notice?
Show answer
Two things should become apparent:
In contrary to the training MSE, which decreases with the order of the model, the test MSE is lowest for the 3rd order model.
The test MSEs are generally higher than the training MSEs. This is to be expected as the intial models did all, to some degree, fit to the noise in the training data.
This is because the 10th order model has too much variance - it is too close to the training data. If we fit such a model to multiple draws of samples from the population with a true association consistent with the cubic order polynomial, the model’s predictive performance will always look different:
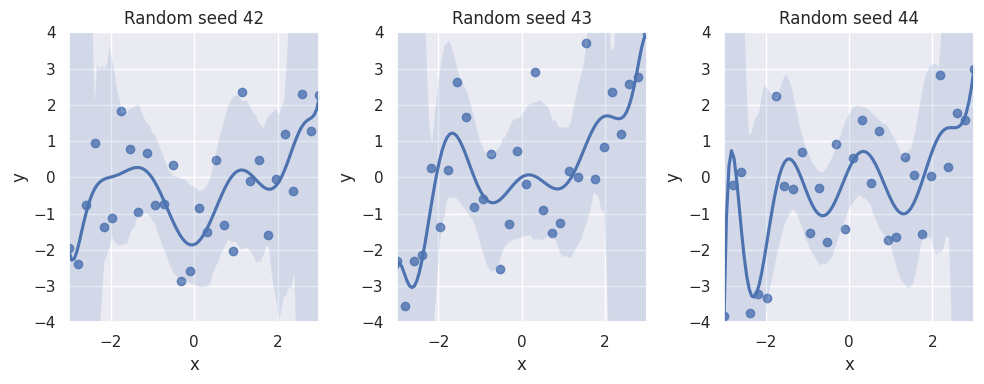
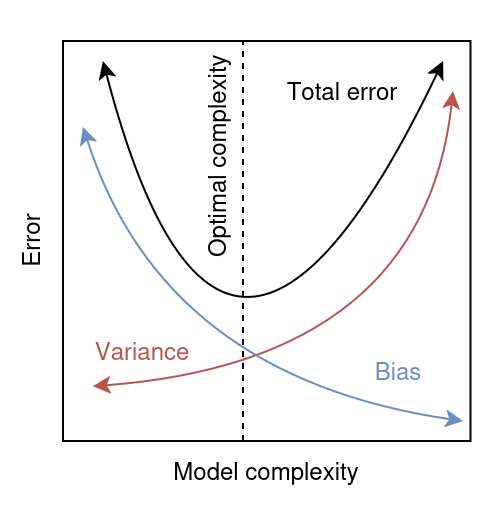
Fig. 2 Bias-variance tradeoff#
When we increase the flexibility of the model by adding more parameters, we are effectively trading between bias and variance. Initially, as the model becomes more flexible, its bias decreases quickly because it can capture more complex patterns in the data. However, this increased flexibility also makes the model more sensitive to the noise in the training data, which leads to a rise in variance.
Eventually, the reduction in bias is no longer sufficient to counterbalance the increase in variance. This is why a model with a very low training MSE may still suffer from a high test MSE: the low training error is primarily a result of fitting the noise (i.e., high variance), rather than capturing a true underlying pattern.
Summary
Our goal is to minimize the reducible error by finding an optimal balance between bias and variance. Only then do we have a model that not only performs well on the training data but also generalizes effectively to new, unseen data.