Modelling Exercises#
Exercise 1: Model Selection#
Today we are working with the California Housing dataset, which you are already familiar with, as we previously used it while exploring resampling method.
This dataset is based on the 1990 U.S. Census and includes features describing California districts.
Familiarize yourself with the data
What kind of features are in the dataset? What is the target?
Baseline model
Create a baseline linear regression model using all features and evaluate the model through 5-fold cross validation, using R² as the performance metric
Print the individual and average R²
Apply a forward stepwise selection to find a simpler suitable model.
Split the data into 80% training data and 20% testing data (print the shape to confirm it was sucessful)
Perform a forward stepwise selection with a linear regression model, 5-fold CV, R² score, and
parsimoniousfeature selection (refer to documentation for further information)Print the best CV R² as well as the chosen features
Evaluate the model on the test set
Exercise 10: SVMs#
For the SVM exercises we will use the fmri dataset from seaborn, which contains measurements of brain activity (signal) in two brain regions (frontal and parietal) under two event types (stim vs. cue).
import seaborn as sns
df = sns.load_dataset("fmri")
df
| subject | timepoint | event | region | signal | |
|---|---|---|---|---|---|
| 0 | s13 | 18 | stim | parietal | -0.017552 |
| 1 | s5 | 14 | stim | parietal | -0.080883 |
| 2 | s12 | 18 | stim | parietal | -0.081033 |
| 3 | s11 | 18 | stim | parietal | -0.046134 |
| 4 | s10 | 18 | stim | parietal | -0.037970 |
| ... | ... | ... | ... | ... | ... |
| 1059 | s0 | 8 | cue | frontal | 0.018165 |
| 1060 | s13 | 7 | cue | frontal | -0.029130 |
| 1061 | s12 | 7 | cue | frontal | -0.004939 |
| 1062 | s11 | 7 | cue | frontal | -0.025367 |
| 1063 | s0 | 0 | cue | parietal | -0.006899 |
1064 rows × 5 columns
We will try to answer a very simple research question:
Can we distinguish between
cueandstimevents based on the fMRI signal in theparietalandfrontalbrain regions?
To do this, we need to turn the long‐format data into a classic “feature matrix” (one row = one sample, two columns = our two brain‐region signals) plus a corresponding label vector (cue/stim):
df_wide = df.pivot_table(
index=["subject","timepoint","event"],
columns="region",
values="signal"
).reset_index()
df_wide.columns.name = None
X = df_wide[["frontal","parietal"]]
y = df_wide["event"].map({"cue":0,"stim":1})
print("\nFeatures:")
print(X.head())
print("\nTarget:")
print(y.head())
Features:
frontal parietal
0 0.007766 -0.006899
1 -0.021452 -0.039327
2 0.016440 0.000300
3 -0.021054 -0.035735
4 0.024296 0.033220
Target:
0 0
1 1
2 0
3 1
4 0
Name: event, dtype: int64
import numpy as np
from sklearn.datasets import fetch_california_housing
from mlxtend.feature_selection import SequentialFeatureSelector
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
# 1) Load the California housing dataset
data = fetch_california_housing(as_frame=True)
X = data.data
y = data.target
# 2) Create baseline model
model = LinearRegression()
scores = cross_val_score(model, X, y, cv=5, scoring='r2')
# Print the results
print("R² scores from each fold:", scores)
print("Average R² score:", np.mean(scores))
# 3) Apply a forward stepwise selection
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(X_train.shape, X_test.shape)
print(y_train.shape, y_test.shape)
# Forward Sequential Feature Selector
sfs_forward = SequentialFeatureSelector(
estimator=LinearRegression(),
k_features="parsimonious",
forward=True,
floating=False,
scoring='r2',
cv=5,
verbose=0)
sfs_forward.fit(X_train, y_train)
print(f">> Forward SFS:")
print(f" Best CV R² : {sfs_forward.k_score_:.3f}")
print(f" Optimal # feats : {len(sfs_forward.k_feature_idx_)}")
print(f" Feature names : {sfs_forward.k_feature_names_}")
# 4) Evaluate the model
selected_features = list(sfs_forward.k_feature_names_)
X_train_selected = X_train[selected_features]
X_test_selected = X_test[selected_features]
# Train and evaluate
model.fit(X_train_selected, y_train)
test_r2 = model.score(X_test_selected, y_test)
print(f"Test R² for the sfs model: {test_r2:.4f}")
R² scores from each fold: [0.54866323 0.46820691 0.55078434 0.53698703 0.66051406]
Average R² score: 0.5530311140279571
(16512, 8) (4128, 8)
(16512,) (4128,)
>> Forward SFS:
Best CV R² : 0.612
Optimal # feats : 7
Feature names : ('MedInc', 'HouseAge', 'AveRooms', 'AveBedrms', 'AveOccup', 'Latitude', 'Longitude')
Test R² for the sfs model: 0.5757
Exercise 2: LASSO#
Please implement a Lasso regression model similar to the Ridge model in the Regularization section.
import pandas as pd
import numpy as np
import statsmodels.api as sm
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LassoCV
from sklearn.model_selection import train_test_split
# Data related processing
hitters = sm.datasets.get_rdataset("Hitters", "ISLR").data
hitters_subset = hitters[["Salary", "AtBat", "Runs","RBI", "CHits", "CAtBat", "CRuns", "CWalks", "Assists", "Hits", "HmRun", "Years", "Errors", "Walks"]].copy()
hitters_subset = hitters_subset.drop(columns=["CRuns", "CAtBat"]) # Remove highly correlated features (see previous session)
hitters_subset.dropna(inplace=True) # drop rows containing missing data
y = hitters_subset["Salary"]
X = hitters_subset.drop(columns=["Salary"])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
scaler = StandardScaler() # Scale predictors to mean=0 and std=1
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Lasso
lambda_range = np.linspace(0.001, 20, 100)
# Get the optimal lambda
lasso_cv = LassoCV(alphas=lambda_range)
lasso_cv.fit(X_train_scaled, y_train)
print(f"Optimal alpha: {lasso_cv.alpha_}\n")
# Get training R²
train_score_ridge= lasso_cv.score(X_train_scaled, y_train)
print(f"Training R²: {train_score_ridge}\n")
# Put the coefficients into a nicely formatted df for visualization
coef_table = pd.DataFrame({
'Predictor': X_train.columns,
'Beta': lasso_cv.coef_
})
coef_table = coef_table.reindex(coef_table['Beta'].abs().sort_values(ascending=False).index)
print(coef_table, "\n")
test_score_ridge= lasso_cv.score(X_test_scaled, y_test)
print(f"Test R²: {test_score_ridge}")
Optimal alpha: 20.0
Training R²: 0.47908195299121104
Predictor Beta
3 CHits 177.984173
6 Hits 101.982447
7 HmRun 52.177420
10 Walks 41.664953
2 RBI 0.000000
0 AtBat 0.000000
1 Runs 0.000000
5 Assists -0.000000
4 CWalks 0.000000
8 Years 0.000000
9 Errors -0.000000
Test R²: 0.31479649243077035
Exercise 3: Principal Component Analysis#
For today’s practical session, we will work with the Diabetes dataset built into scikit-learn. This dataset contains medical information from 442 diabetes patients:
Features (X): 10 baseline variables (age, sex, BMI, average blood pressure, and six blood serum measures).
Target (y): a quantitative measure of disease progression one year after baseline.
You can read more here: https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_diabetes.html
Tasks:
Inspect & clean (already implemented)
Display summary statistics (
df.describe()) for all 10 features.Check for missing values. (Hint: this dataset has none, but verify.)
Standardize
Use
StandardScaler()to transform each feature to mean 0, variance 1.
PCA & scree plot
Fit
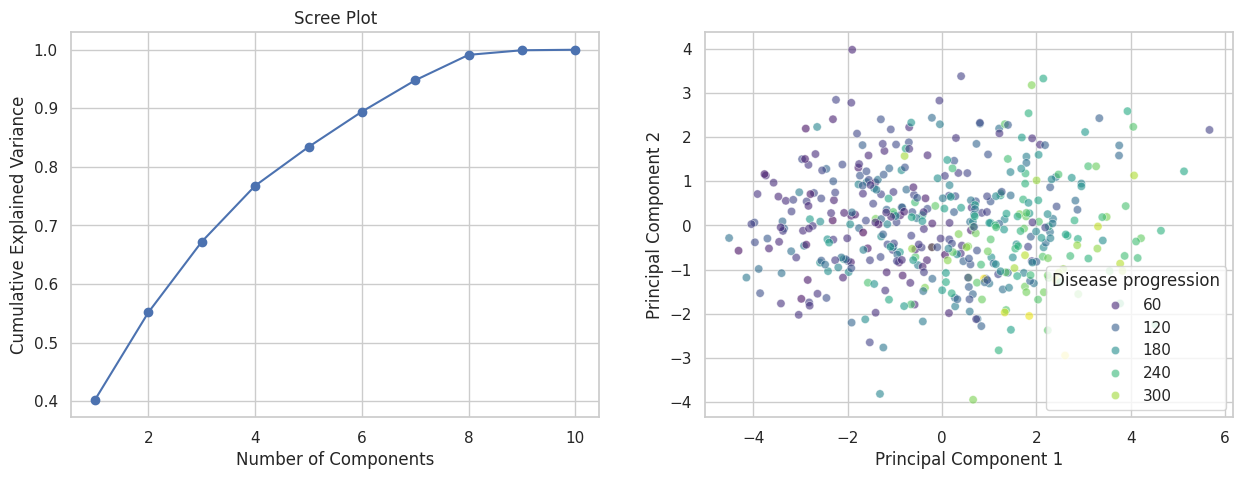
PCA()to the standardized feature matrix.Plot the explained variance ratio for each principal component (a scree plot).
Decide how many components to retain (e.g.\ cumulative variance ≥ 80%).
Interpret loadings
Examine
pca.components_.For the first two retained PCs, list the top 3 features by absolute loading.
Infer what physiological patterns these components might represent.
Project the data for visualization
Compute the PCA projection:
X_pca = pca.transform(X_std).
Plot the results (already implemented)
Create a 2D scatter of PC1 vs. PC2, coloring points by whether the target is above or below the median progression value.
Do patients with more rapid progression cluster differently?
from sklearn.datasets import load_diabetes
# Load the data as a DataFrame
diabetes = load_diabetes(as_frame=True)
df = diabetes.frame
df.rename(columns={'target': 'Disease progression'}, inplace=True)
X = df.drop(columns='Disease progression')
y = df['Disease progression']
# 1. Inspect the data
df.head()
| age | sex | bmi | bp | s1 | s2 | s3 | s4 | s5 | s6 | Disease progression | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.038076 | 0.050680 | 0.061696 | 0.021872 | -0.044223 | -0.034821 | -0.043401 | -0.002592 | 0.019907 | -0.017646 | 151.0 |
| 1 | -0.001882 | -0.044642 | -0.051474 | -0.026328 | -0.008449 | -0.019163 | 0.074412 | -0.039493 | -0.068332 | -0.092204 | 75.0 |
| 2 | 0.085299 | 0.050680 | 0.044451 | -0.005670 | -0.045599 | -0.034194 | -0.032356 | -0.002592 | 0.002861 | -0.025930 | 141.0 |
| 3 | -0.089063 | -0.044642 | -0.011595 | -0.036656 | 0.012191 | 0.024991 | -0.036038 | 0.034309 | 0.022688 | -0.009362 | 206.0 |
| 4 | 0.005383 | -0.044642 | -0.036385 | 0.021872 | 0.003935 | 0.015596 | 0.008142 | -0.002592 | -0.031988 | -0.046641 | 135.0 |
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import seaborn as sns
sns.set_theme(style="whitegrid")
# 1. Standardize the data
scaler = StandardScaler()
X_std = scaler.fit_transform(X)
# 2. Perform the PCA
pca = PCA()
pca.fit(X_std)
# 3. Get the explained variance ratio
explained_variance = pca.explained_variance_ratio_
# 4. Project into PCA space
X_pca = pca.transform(X_std)
# 5. Plot the explained variance and 2D PCA projection
fig, ax = plt.subplots(1,2, figsize=(15, 5))
ax[0].plot(np.arange(1, len(explained_variance)+1), explained_variance.cumsum(), marker='o')
ax[0].set(xlabel='Number of Components', ylabel='Cumulative Explained Variance', title='Scree Plot')
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=y, palette='viridis', alpha=0.6, ax=ax[1])
ax[1].set(xlabel='Principal Component 1', ylabel='Principal Component 2');
Exercise 3.2: PCR and PLS#
In this exercise, we will compare PCR and PLS on the classic Diabetes dataset from scikit-learn. This dataset contains 10 baseline variables (age, BMI, blood pressure, etc.) and a quantitative target: a measure of disease progression one year after baseline.
Start by loading the data and extracting the features (X) as well as the target (y):
from sklearn.datasets import load_diabetes
import pandas as pd
import matplotlib.pyplot as plt
data = load_diabetes(as_frame=True)
X = data.data
y = data.target
X.head()
| age | sex | bmi | bp | s1 | s2 | s3 | s4 | s5 | s6 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.038076 | 0.050680 | 0.061696 | 0.021872 | -0.044223 | -0.034821 | -0.043401 | -0.002592 | 0.019907 | -0.017646 |
| 1 | -0.001882 | -0.044642 | -0.051474 | -0.026328 | -0.008449 | -0.019163 | 0.074412 | -0.039493 | -0.068332 | -0.092204 |
| 2 | 0.085299 | 0.050680 | 0.044451 | -0.005670 | -0.045599 | -0.034194 | -0.032356 | -0.002592 | 0.002861 | -0.025930 |
| 3 | -0.089063 | -0.044642 | -0.011595 | -0.036656 | 0.012191 | 0.024991 | -0.036038 | 0.034309 | 0.022688 | -0.009362 |
| 4 | 0.005383 | -0.044642 | -0.036385 | 0.021872 | 0.003935 | 0.015596 | 0.008142 | -0.002592 | -0.031988 | -0.046641 |
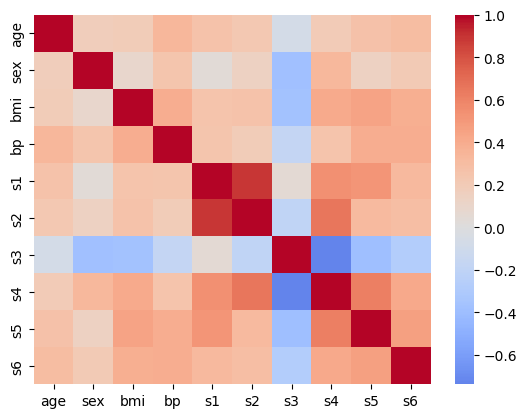
How many predictors does the dataset have? Are any of them obviously correlated? Visualize them with a correlation matrix/heatmap.
import seaborn as sns
sns.heatmap(X.corr(), cmap="coolwarm", center=0);
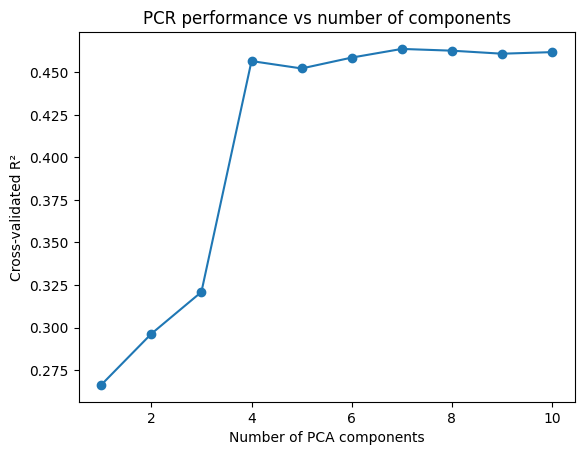
Please apply PCR with a range of component numbers to see how the performance changes.
Use 10-fold CV
Try 1 to 10 components
Create a model pipeline with
make_pipeline()Evaluate the models with
cross_val_score()Plot the \(R^2\) over the components
from sklearn.decomposition import PCA
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_score, KFold
import numpy as np
cv = KFold(n_splits=10)
n_components = np.arange(1, X.shape[1] + 1)
pcr_scores = []
for n in n_components:
model = make_pipeline(StandardScaler(), PCA(n_components=n), LinearRegression())
scores = cross_val_score(model, X, y, cv=cv, scoring="r2")
pcr_scores.append(scores.mean())
# Plot
fig, ax = plt.subplots()
ax.plot(n_components, pcr_scores, marker="o")
ax.set(xlabel="Number of PCA components", ylabel="Cross-validated R²", title="PCR performance vs number of components");
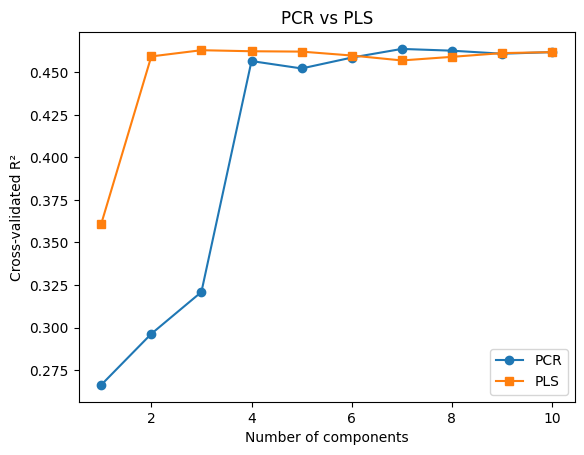
Now, do the exact same thing with PLSRegression. How does PLS compare to PCR?
from sklearn.cross_decomposition import PLSRegression
pls_scores = []
for n in n_components:
pls = PLSRegression(n_components=n)
scores = cross_val_score(pls, X, y, cv=cv, scoring="r2")
pls_scores.append(scores.mean())
# Plot
fig, ax = plt.subplots()
ax.plot(n_components, pcr_scores, marker="o", label="PCR")
ax.plot(n_components, pls_scores, marker="s", label="PLS")
ax.set(xlabel="Number of components", ylabel="Cross-validated R²", title="PCR vs PLS")
plt.legend();
Exercise 4: Logistic Regression#
For today’s exercise we will use the Breast Cancer Wisconsin (Diagnostic). It is a collection of data used for predicting whether a breast tumor is malignant (cancerous) or benign (non-cancerous), containing information derived from images of breast mass samples obtained through fine needle aspirates.
The dataset consists of 569 samples with 30 features that measure various characteristics of cell nuclei, such as radius, texture, perimeter, and area. Each sample is labeled as either malignant (1) or benign (0).
Please visit the documentation and familiarize yourself with the dataset
Take an initial look at the features (predictors) and targets (outcomes)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
from ucimlrepo import fetch_ucirepo
# Fetch dataset
breast_cancer_wisconsin_diagnostic = fetch_ucirepo(id=17)
# Get data (as pandas dataframes)
X = breast_cancer_wisconsin_diagnostic.data.features
y = breast_cancer_wisconsin_diagnostic.data.targets
# Convert y to a 1D array (this is the required input for the logistic regression model)
y = np.ravel(y)
breast_cancer_wisconsin_diagnostic.variables
| name | role | type | demographic | description | units | missing_values | |
|---|---|---|---|---|---|---|---|
| 0 | ID | ID | Categorical | None | None | None | no |
| 1 | Diagnosis | Target | Categorical | None | None | None | no |
| 2 | radius1 | Feature | Continuous | None | None | None | no |
| 3 | texture1 | Feature | Continuous | None | None | None | no |
| 4 | perimeter1 | Feature | Continuous | None | None | None | no |
| 5 | area1 | Feature | Continuous | None | None | None | no |
| 6 | smoothness1 | Feature | Continuous | None | None | None | no |
| 7 | compactness1 | Feature | Continuous | None | None | None | no |
| 8 | concavity1 | Feature | Continuous | None | None | None | no |
| 9 | concave_points1 | Feature | Continuous | None | None | None | no |
| 10 | symmetry1 | Feature | Continuous | None | None | None | no |
| 11 | fractal_dimension1 | Feature | Continuous | None | None | None | no |
| 12 | radius2 | Feature | Continuous | None | None | None | no |
| 13 | texture2 | Feature | Continuous | None | None | None | no |
| 14 | perimeter2 | Feature | Continuous | None | None | None | no |
| 15 | area2 | Feature | Continuous | None | None | None | no |
| 16 | smoothness2 | Feature | Continuous | None | None | None | no |
| 17 | compactness2 | Feature | Continuous | None | None | None | no |
| 18 | concavity2 | Feature | Continuous | None | None | None | no |
| 19 | concave_points2 | Feature | Continuous | None | None | None | no |
| 20 | symmetry2 | Feature | Continuous | None | None | None | no |
| 21 | fractal_dimension2 | Feature | Continuous | None | None | None | no |
| 22 | radius3 | Feature | Continuous | None | None | None | no |
| 23 | texture3 | Feature | Continuous | None | None | None | no |
| 24 | perimeter3 | Feature | Continuous | None | None | None | no |
| 25 | area3 | Feature | Continuous | None | None | None | no |
| 26 | smoothness3 | Feature | Continuous | None | None | None | no |
| 27 | compactness3 | Feature | Continuous | None | None | None | no |
| 28 | concavity3 | Feature | Continuous | None | None | None | no |
| 29 | concave_points3 | Feature | Continuous | None | None | None | no |
| 30 | symmetry3 | Feature | Continuous | None | None | None | no |
| 31 | fractal_dimension3 | Feature | Continuous | None | None | None | no |
X.head()
| radius1 | texture1 | perimeter1 | area1 | smoothness1 | compactness1 | concavity1 | concave_points1 | symmetry1 | fractal_dimension1 | ... | radius3 | texture3 | perimeter3 | area3 | smoothness3 | compactness3 | concavity3 | concave_points3 | symmetry3 | fractal_dimension3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.3001 | 0.14710 | 0.2419 | 0.07871 | ... | 25.38 | 17.33 | 184.60 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.11890 |
| 1 | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.0869 | 0.07017 | 0.1812 | 0.05667 | ... | 24.99 | 23.41 | 158.80 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.08902 |
| 2 | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.1974 | 0.12790 | 0.2069 | 0.05999 | ... | 23.57 | 25.53 | 152.50 | 1709.0 | 0.1444 | 0.4245 | 0.4504 | 0.2430 | 0.3613 | 0.08758 |
| 3 | 11.42 | 20.38 | 77.58 | 386.1 | 0.14250 | 0.28390 | 0.2414 | 0.10520 | 0.2597 | 0.09744 | ... | 14.91 | 26.50 | 98.87 | 567.7 | 0.2098 | 0.8663 | 0.6869 | 0.2575 | 0.6638 | 0.17300 |
| 4 | 20.29 | 14.34 | 135.10 | 1297.0 | 0.10030 | 0.13280 | 0.1980 | 0.10430 | 0.1809 | 0.05883 | ... | 22.54 | 16.67 | 152.20 | 1575.0 | 0.1374 | 0.2050 | 0.4000 | 0.1625 | 0.2364 | 0.07678 |
5 rows × 30 columns
X.describe()
| radius1 | texture1 | perimeter1 | area1 | smoothness1 | compactness1 | concavity1 | concave_points1 | symmetry1 | fractal_dimension1 | ... | radius3 | texture3 | perimeter3 | area3 | smoothness3 | compactness3 | concavity3 | concave_points3 | symmetry3 | fractal_dimension3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 569.000000 | 569.000000 | 569.000000 | 569.000000 | 569.000000 | 569.000000 | 569.000000 | 569.000000 | 569.000000 | 569.000000 | ... | 569.000000 | 569.000000 | 569.000000 | 569.000000 | 569.000000 | 569.000000 | 569.000000 | 569.000000 | 569.000000 | 569.000000 |
| mean | 14.127292 | 19.289649 | 91.969033 | 654.889104 | 0.096360 | 0.104341 | 0.088799 | 0.048919 | 0.181162 | 0.062798 | ... | 16.269190 | 25.677223 | 107.261213 | 880.583128 | 0.132369 | 0.254265 | 0.272188 | 0.114606 | 0.290076 | 0.083946 |
| std | 3.524049 | 4.301036 | 24.298981 | 351.914129 | 0.014064 | 0.052813 | 0.079720 | 0.038803 | 0.027414 | 0.007060 | ... | 4.833242 | 6.146258 | 33.602542 | 569.356993 | 0.022832 | 0.157336 | 0.208624 | 0.065732 | 0.061867 | 0.018061 |
| min | 6.981000 | 9.710000 | 43.790000 | 143.500000 | 0.052630 | 0.019380 | 0.000000 | 0.000000 | 0.106000 | 0.049960 | ... | 7.930000 | 12.020000 | 50.410000 | 185.200000 | 0.071170 | 0.027290 | 0.000000 | 0.000000 | 0.156500 | 0.055040 |
| 25% | 11.700000 | 16.170000 | 75.170000 | 420.300000 | 0.086370 | 0.064920 | 0.029560 | 0.020310 | 0.161900 | 0.057700 | ... | 13.010000 | 21.080000 | 84.110000 | 515.300000 | 0.116600 | 0.147200 | 0.114500 | 0.064930 | 0.250400 | 0.071460 |
| 50% | 13.370000 | 18.840000 | 86.240000 | 551.100000 | 0.095870 | 0.092630 | 0.061540 | 0.033500 | 0.179200 | 0.061540 | ... | 14.970000 | 25.410000 | 97.660000 | 686.500000 | 0.131300 | 0.211900 | 0.226700 | 0.099930 | 0.282200 | 0.080040 |
| 75% | 15.780000 | 21.800000 | 104.100000 | 782.700000 | 0.105300 | 0.130400 | 0.130700 | 0.074000 | 0.195700 | 0.066120 | ... | 18.790000 | 29.720000 | 125.400000 | 1084.000000 | 0.146000 | 0.339100 | 0.382900 | 0.161400 | 0.317900 | 0.092080 |
| max | 28.110000 | 39.280000 | 188.500000 | 2501.000000 | 0.163400 | 0.345400 | 0.426800 | 0.201200 | 0.304000 | 0.097440 | ... | 36.040000 | 49.540000 | 251.200000 | 4254.000000 | 0.222600 | 1.058000 | 1.252000 | 0.291000 | 0.663800 | 0.207500 |
8 rows × 30 columns
y
array(['M', 'M', 'M', 'M', 'M', 'M', 'M', 'M', 'M', 'M', 'M', 'M', 'M',
'M', 'M', 'M', 'M', 'M', 'M', 'B', 'B', 'B', 'M', 'M', 'M', 'M',
'M', 'M', 'M', 'M', 'M', 'M', 'M', 'M', 'M', 'M', 'M', 'B', 'M',
'M', 'M', 'M', 'M', 'M', 'M', 'M', 'B', 'M', 'B', 'B', 'B', 'B',
'B', 'M', 'M', 'B', 'M', 'M', 'B', 'B', 'B', 'B', 'M', 'B', 'M',
'M', 'B', 'B', 'B', 'B', 'M', 'B', 'M', 'M', 'B', 'M', 'B', 'M',
'M', 'B', 'B', 'B', 'M', 'M', 'B', 'M', 'M', 'M', 'B', 'B', 'B',
'M', 'B', 'B', 'M', 'M', 'B', 'B', 'B', 'M', 'M', 'B', 'B', 'B',
'B', 'M', 'B', 'B', 'M', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B',
'M', 'M', 'M', 'B', 'M', 'M', 'B', 'B', 'B', 'M', 'M', 'B', 'M',
'B', 'M', 'M', 'B', 'M', 'M', 'B', 'B', 'M', 'B', 'B', 'M', 'B',
'B', 'B', 'B', 'M', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B',
'M', 'B', 'B', 'B', 'B', 'M', 'M', 'B', 'M', 'B', 'B', 'M', 'M',
'B', 'B', 'M', 'M', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'M', 'M',
'M', 'B', 'M', 'B', 'M', 'B', 'B', 'B', 'M', 'B', 'B', 'M', 'M',
'B', 'M', 'M', 'M', 'M', 'B', 'M', 'M', 'M', 'B', 'M', 'B', 'M',
'B', 'B', 'M', 'B', 'M', 'M', 'M', 'M', 'B', 'B', 'M', 'M', 'B',
'B', 'B', 'M', 'B', 'B', 'B', 'B', 'B', 'M', 'M', 'B', 'B', 'M',
'B', 'B', 'M', 'M', 'B', 'M', 'B', 'B', 'B', 'B', 'M', 'B', 'B',
'B', 'B', 'B', 'M', 'B', 'M', 'M', 'M', 'M', 'M', 'M', 'M', 'M',
'M', 'M', 'M', 'M', 'M', 'M', 'B', 'B', 'B', 'B', 'B', 'B', 'M',
'B', 'M', 'B', 'B', 'M', 'B', 'B', 'M', 'B', 'M', 'M', 'B', 'B',
'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'M', 'B',
'B', 'M', 'B', 'M', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B',
'B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'B', 'M', 'B', 'M', 'B',
'B', 'B', 'B', 'M', 'M', 'M', 'B', 'B', 'B', 'B', 'M', 'B', 'M',
'B', 'M', 'B', 'B', 'B', 'M', 'B', 'B', 'B', 'B', 'B', 'B', 'B',
'M', 'M', 'M', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B',
'B', 'M', 'M', 'B', 'M', 'M', 'M', 'B', 'M', 'M', 'B', 'B', 'B',
'B', 'B', 'M', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'B', 'M',
'B', 'B', 'M', 'M', 'B', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'B',
'B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'B', 'B', 'B', 'M', 'B',
'B', 'M', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B',
'B', 'M', 'B', 'M', 'M', 'B', 'M', 'B', 'B', 'B', 'B', 'B', 'M',
'B', 'B', 'M', 'B', 'M', 'B', 'B', 'M', 'B', 'M', 'B', 'B', 'B',
'B', 'B', 'B', 'B', 'B', 'M', 'M', 'B', 'B', 'B', 'B', 'B', 'B',
'M', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'M', 'B',
'B', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'M', 'B', 'B', 'M', 'B',
'B', 'B', 'B', 'B', 'M', 'M', 'B', 'M', 'B', 'M', 'B', 'B', 'B',
'B', 'B', 'M', 'B', 'B', 'M', 'B', 'M', 'B', 'M', 'M', 'B', 'B',
'B', 'M', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B',
'M', 'B', 'M', 'M', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B',
'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B',
'B', 'B', 'B', 'M', 'M', 'M', 'M', 'M', 'M', 'B'], dtype=object)
Split the data into training and test sets (stratify
y)Create and fit a baseline model using only 2-3 interpretable predictors of your choice
Print the model coefficients
Evaluate on the test set:
Accuracy
Confusion matrix
Classification report
Compare test accuracy to train accuracy. Is there a big gap?
Hint: If you get a warning about convergence, try setting max_iter=10000 in the logistic regression class.
# 1. Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
# 2. Baseline model with three features
features_baseline = ["radius1", "texture1", "area1"]
X_train_base = X_train[features_baseline]
X_test_base = X_test[features_baseline]
baseline_model = LogisticRegression(max_iter=10000)
baseline_model.fit(X_train_base, y_train)
intercept = baseline_model.intercept_
coef = baseline_model.coef_
print("Intercept:", intercept)
print("Coefficients:", coef)
# 3. Evaluate the baseline model
# Accuracy on the test set with baseline features
print("Test accuracy (baseline):", baseline_model.score(X_test_base, y_test))
# Predictions on the test set
y_pred_test_base = baseline_model.predict(X_test_base)
# Confusion matrix on the test set
conf = confusion_matrix(y_test, y_pred_test_base)
print("Confusion matrix (test):\n", conf)
# Classification report on the test set
report = classification_report(y_test, y_pred_test_base, target_names=["Benign", "Malignant"])
print(report)
Intercept: [-10.51351325]
Coefficients: [[-0.22529272 0.21197004 0.01417093]]
Test accuracy (baseline): 0.8508771929824561
Confusion matrix (test):
[[68 4]
[13 29]]
precision recall f1-score support
Benign 0.84 0.94 0.89 72
Malignant 0.88 0.69 0.77 42
accuracy 0.85 114
macro avg 0.86 0.82 0.83 114
weighted avg 0.85 0.85 0.85 114
Use all predictors and build a pipeline with standardisation
Evaluate on the test set
Compare:
Baseline model vs full model (test accuracy, precision, recall for malignant)
Is the full model clearly better?
Is there any sign of overfitting (train vs test)?
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
# 4. Full model with all features
full_model = Pipeline(steps=[
("scaler", StandardScaler()),
("logreg", LogisticRegression(max_iter=10000))
])
full_model.fit(X_train, y_train)
# 5. Evaluate the full model
y_pred_test = full_model.predict(X_test)
print("Test accuracy:", accuracy_score(y_test, y_pred_test))
print("Confusion matrix:\n", confusion_matrix(y_test, y_pred_test))
print(classification_report(y_test, y_pred_test, target_names=["Benign", "Malignant"]))
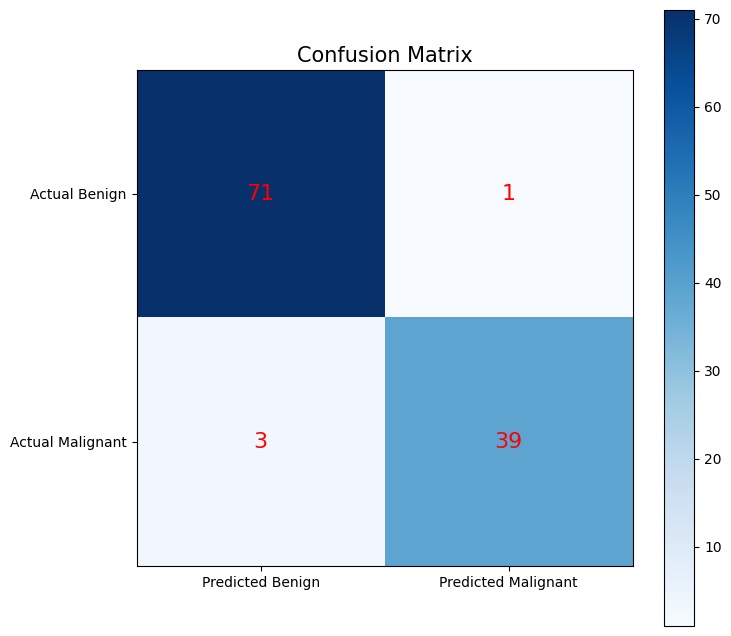
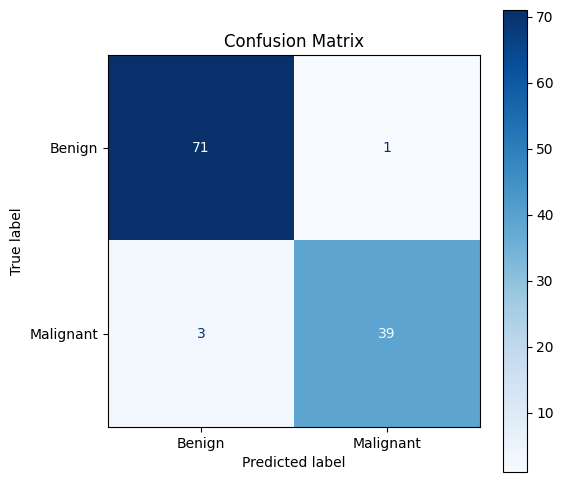
Test accuracy: 0.9649122807017544
Confusion matrix:
[[71 1]
[ 3 39]]
precision recall f1-score support
Benign 0.96 0.99 0.97 72
Malignant 0.97 0.93 0.95 42
accuracy 0.96 114
macro avg 0.97 0.96 0.96 114
weighted avg 0.97 0.96 0.96 114
Create a custom plot which visualizes the confusion matrix It should contain:
The four squares of the matrix (color coded)
Labels of the actual values in the middle of each square
Labels for all squares
A colorbar
A title
Use scikit-learn to do the same
# 6. Plot a custom confusion matrix
conf = confusion_matrix(y_test, y_pred_test)
fig, ax = plt.subplots(figsize=(8, 8))
cax = ax.imshow(conf, cmap='Blues')
# labels
ax.xaxis.set(ticks=(0, 1), ticklabels=('Predicted Benign', 'Predicted Malignant'))
ax.yaxis.set(ticks=(0, 1), ticklabels=('Actual Benign', 'Actual Malignant'))
# Annotate the confusion matrix
for i in range(2):
for j in range(2):
ax.text(j, i, conf[i, j], ha='center', va='center', color='red', fontsize=16)
ax.set_title('Confusion Matrix', fontsize=15)
plt.colorbar(cax)
plt.show()
# 6. Use scikit-learn
from sklearn.metrics import ConfusionMatrixDisplay
# Display the confusion matrix using scikit-learn
fig, ax = plt.subplots(figsize=(6, 6))
disp = ConfusionMatrixDisplay(confusion_matrix=conf,
display_labels=["Benign", "Malignant"])
disp.plot(cmap='Blues', ax=ax, colorbar=True)
plt.title("Confusion Matrix")
plt.show()
Exercise 5: LDA, QDA & Naïve Bayes#
Once again, we will use the Iris dataset for classificationa analysis. Your task is to compare the performance of LDA, QDA, and Gaussian Naïve Bayes!
Load the
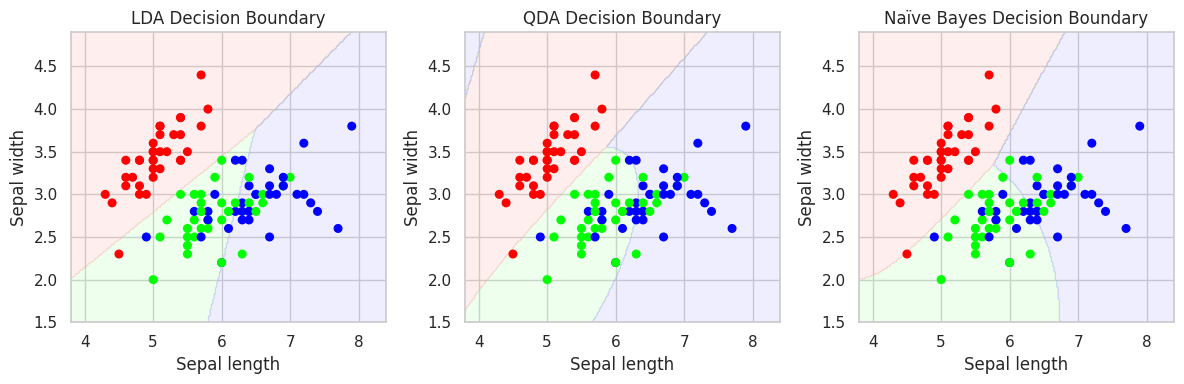
irisdataset fromsklearn.datasets. We will use only the first two features (sepal length and width)TODO:Split the data into training and test sets (use stratification!)TODO:Fit LDA, QDA, and Naïve Bayes classifiers to the training data and orint the classification report for all models on the test dataPlot the decision boundaries for both models
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
from matplotlib.colors import ListedColormap
# 1. Load data
iris = load_iris()
X = iris.data[:, :2]
y = iris.target
target_names = iris.target_names
# 2. Split into train/test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, stratify=y, random_state=123)
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
# 3. TODO: Fit a LDA model and print the classification report
lda = LinearDiscriminantAnalysis()
lda.fit(X_train, y_train)
print(classification_report(y_test, lda.predict(X_test)))
precision recall f1-score support
0 1.00 1.00 1.00 15
1 0.69 0.60 0.64 15
2 0.65 0.73 0.69 15
accuracy 0.78 45
macro avg 0.78 0.78 0.78 45
weighted avg 0.78 0.78 0.78 45
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
# 3. TODO: Fit a QDA model and print the classification report
qda = QuadraticDiscriminantAnalysis()
qda.fit(X_train, y_train)
print(classification_report(y_test, qda.predict(X_test)))
precision recall f1-score support
0 1.00 1.00 1.00 15
1 0.73 0.53 0.62 15
2 0.63 0.80 0.71 15
accuracy 0.78 45
macro avg 0.79 0.78 0.77 45
weighted avg 0.79 0.78 0.77 45
from sklearn.naive_bayes import GaussianNB
# 3. TODO: Fit a Gaussian Naive Bayes model and print the classification report
gnb = GaussianNB()
gnb.fit(X_train, y_train)
print(classification_report(y_test, gnb.predict(X_test)))
precision recall f1-score support
0 1.00 1.00 1.00 15
1 0.71 0.67 0.69 15
2 0.69 0.73 0.71 15
accuracy 0.80 45
macro avg 0.80 0.80 0.80 45
weighted avg 0.80 0.80 0.80 45
# 4. Plot the decision boundaries for all 3 classifiers
# Plotting function
def plot_decision_boundary(model, X, y, title, ax):
h = .02
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])
ax.contourf(xx, yy, Z, cmap=cmap_light, alpha=0.2)
scatter = ax.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap_bold, s=30)
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
ax.set_title(title)
ax.set_xlabel('Sepal length')
ax.set_ylabel('Sepal width')
# Create plots for all 3 classifiers
fig, axes = plt.subplots(1, 3, figsize=(12, 4))
plot_decision_boundary(lda, X_train, y_train, "LDA Decision Boundary", axes[0])
plot_decision_boundary(qda, X_train, y_train, "QDA Decision Boundary", axes[1])
plot_decision_boundary(gnb, X_train, y_train, "Naïve Bayes Decision Boundary", axes[2])
plt.tight_layout()
Exercise 6: Polynomial and Flexible Regression#
In this exercise, we analyse the relationship between wage and age using four flexible regression approaches:
Polynomial regression
Stepwise functions (degree-0 splines)
Spline regression
Local regression (LOWESS)
We will use the Wage dataset for the following exercises. Please briefly visit the documentation for further information: https://rdrr.io/cran/ISLR/man/Wage.html
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
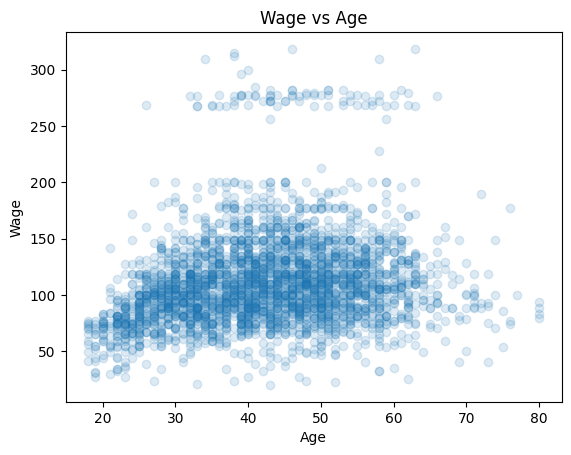
wage = sm.datasets.get_rdataset("Wage", "ISLR").data
fig, ax = plt.subplots()
ax.scatter(wage["age"], wage["wage"], alpha=0.15)
ax.set(xlabel="Age", ylabel="Wage", title="Wage vs Age");
wage.head()
| year | age | maritl | race | education | region | jobclass | health | health_ins | logwage | wage | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| rownames | |||||||||||
| 231655 | 2006 | 18 | 1. Never Married | 1. White | 1. < HS Grad | 2. Middle Atlantic | 1. Industrial | 1. <=Good | 2. No | 4.318063 | 75.043154 |
| 86582 | 2004 | 24 | 1. Never Married | 1. White | 4. College Grad | 2. Middle Atlantic | 2. Information | 2. >=Very Good | 2. No | 4.255273 | 70.476020 |
| 161300 | 2003 | 45 | 2. Married | 1. White | 3. Some College | 2. Middle Atlantic | 1. Industrial | 1. <=Good | 1. Yes | 4.875061 | 130.982177 |
| 155159 | 2003 | 43 | 2. Married | 3. Asian | 4. College Grad | 2. Middle Atlantic | 2. Information | 2. >=Very Good | 1. Yes | 5.041393 | 154.685293 |
| 11443 | 2005 | 50 | 4. Divorced | 1. White | 2. HS Grad | 2. Middle Atlantic | 2. Information | 1. <=Good | 1. Yes | 4.318063 | 75.043154 |
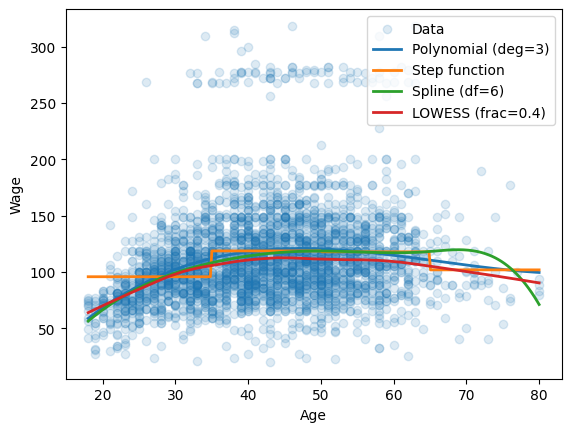
Please predict Wage from Age using four different models:
A polynomial regression model of degree 3
A stepwise model with cut points at 30, 50, and 65 years
A third order spline regression model with
df=6A lowes local regression model with
frac=0.4
Plot the resulting model fits in a single figure.
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
poly = PolynomialFeatures(degree=3, include_bias=False)
X_poly = poly.fit_transform(wage[["age"]])
poly_mod = LinearRegression().fit(X_poly, wage["wage"])
import patsy
import statsmodels.api as sm
cuts = [35, 50, 65]
step_basis = patsy.dmatrix(
"bs(age, knots=cuts, degree=0, include_intercept=False)",
{"age": wage["age"], "cuts": cuts},
return_type="dataframe",
)
step_mod = sm.OLS(wage["wage"], step_basis).fit()
spline_basis = patsy.dmatrix(
"bs(age, df=6, degree=3, include_intercept=False)",
{"age": wage["age"]},
return_type="dataframe",
)
spline_mod = sm.OLS(wage["wage"], spline_basis).fit()
from statsmodels.nonparametric.smoothers_lowess import lowess
low_mod = lowess(wage["wage"], wage["age"], frac=0.4)
Plot the models:
age_grid = np.linspace(wage["age"].min(), wage["age"].max(), 300)
# Polynomial predictions
poly_pred = poly_mod.predict(poly.transform(age_grid.reshape(-1, 1)))
# Stepwise predictions
step_grid = patsy.dmatrix(
"bs(x, knots=cuts, degree=0, include_intercept=False)",
{"x": age_grid, "cuts": cuts},
return_type="dataframe",
)
step_pred = step_mod.predict(step_grid)
# Spline predictions
spline_grid = patsy.dmatrix(
"bs(x, df=6, degree=3, include_intercept=False)",
{"x": age_grid},
return_type="dataframe",
)
spline_pred = spline_mod.predict(spline_grid)
fig, ax = plt.subplots()
ax.scatter(wage["age"], wage["wage"], alpha=0.15, label="Data")
ax.plot(age_grid, poly_pred, label="Polynomial (deg=3)", linewidth=2)
ax.plot(age_grid, step_pred, label="Step function", linewidth=2)
ax.plot(age_grid, spline_pred, label="Spline (df=6)", linewidth=2)
ax.plot(low_mod[:,0], low_mod[:,1], label="LOWESS (frac=0.4)", linewidth=2)
ax.set(xlabel="Age", ylabel="Wage")
plt.legend();
/home/mibur/miniconda3/envs/psy111/lib/python3.13/site-packages/sklearn/base.py:493: UserWarning: X does not have valid feature names, but PolynomialFeatures was fitted with feature names
warnings.warn(
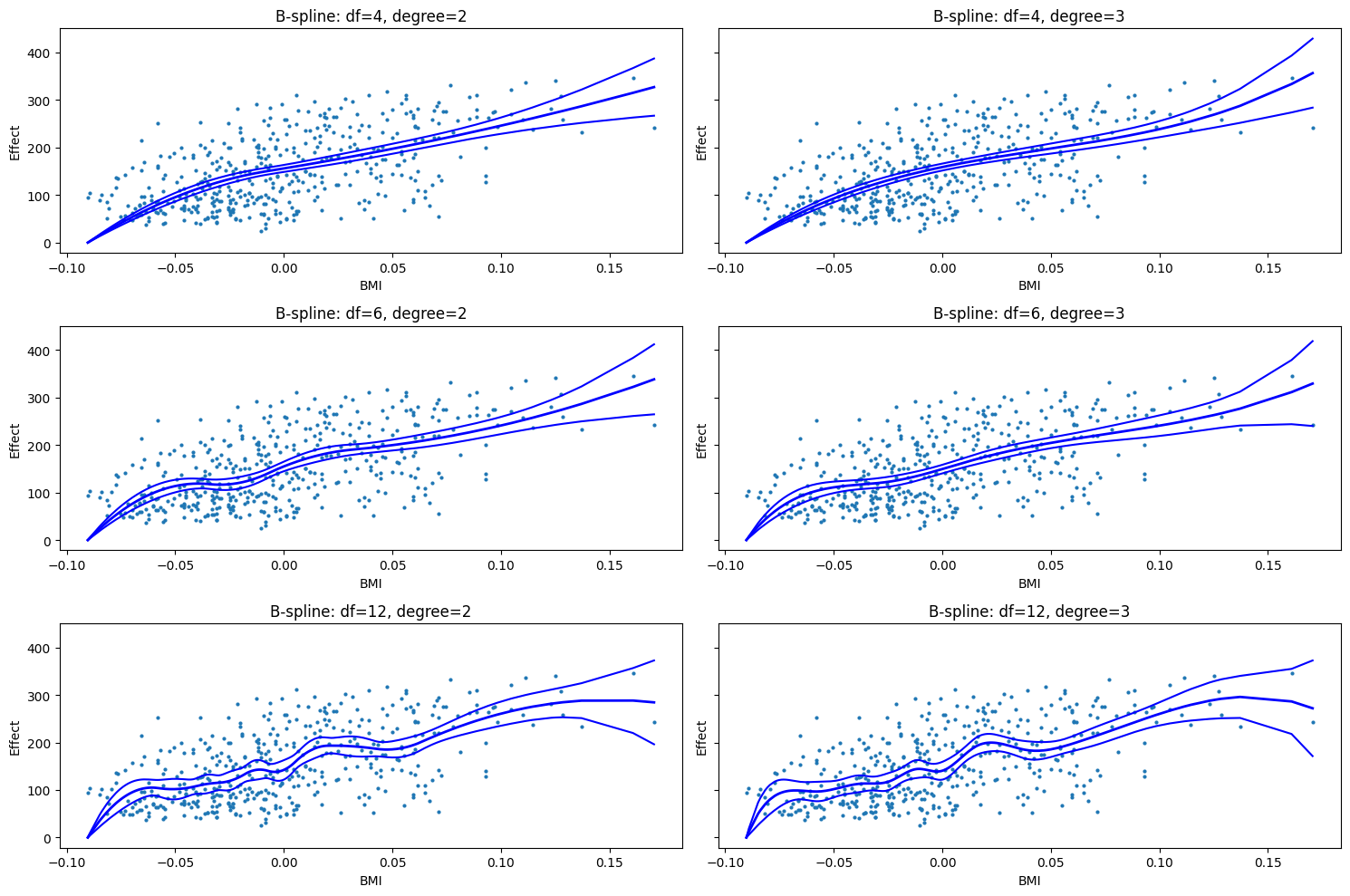
Exercise 7: Generalized Additive Models#
Objective: Understand how the number of basis functions (df) and the polynomial degree (degree) affect the flexibility of a spline and the resulting fit in a Generalized Additive Model.
Use the diabetes dataset and focus on the relationship between
bmiandtarget.We want to test different combinations of parameters. For the dfs, please use 4, 6, 12. For the degree, please use 2 and 3 (quadratic and cubic).
Fit the GAMs for each parameter combination. The resulting models will be plotted automatically for visual comparison.
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from statsmodels.gam.api import GLMGam, BSplines
# 1. Get bmi as x and the target as y
data = load_diabetes(as_frame=True)
x = data.data[['bmi']]
y = data.target
# 2. Define possible parameters
df_values = [4, 6, 12]
degree_values = [2, 3]
# 3. PLot partial effect for each combination of df and degree
fig, axes = plt.subplots(len(df_values), len(degree_values), figsize=(15, 10), sharey=True)
for i, df_val in enumerate(df_values):
for j, deg_val in enumerate(degree_values):
bs = BSplines(x, df=df_val, degree=deg_val)
gam = GLMGam(y, smoother=bs)
res = gam.fit()
res.plot_partial(0, cpr=True, ax=axes[i, j])
axes[i, j].set_title(f'B-spline: df={df_val}, degree={deg_val}')
axes[i, j].set_xlabel('BMI')
axes[i, j].set_ylabel('Effect')
plt.tight_layout()
plt.show()
We now use the wage dataset, which contains income information for a group of workers, along with demographic and employment-related features such as age, education, marital status, and job class.
Explore the dataset
Which variables are numeric?
Which ones are categorical?
Fit a GAM predicting
wagefromage,year,education,jobclass, andmaritl
Note: For categorical features we use a one-hot encoding with pd.get_dummies()
import pandas as pd
from ISLP import load_data
from statsmodels.gam.api import GLMGam, BSplines
# Load data
Wage = load_data('Wage')
# Continuous features
spline_features = ['age', 'year']
X_spline = Wage[spline_features]
# Categorical features — one-hot encode
categoricals = ['education', 'jobclass', 'maritl']
X_cat = pd.get_dummies(Wage[categoricals], drop_first=True)
# Outcome
y = Wage['wage']
# Create BSpline basis
bs = BSplines(X_spline, df=[6]*len(spline_features), degree=[3]*len(spline_features))
# Fit GAM
gam = GLMGam(y, exog=X_cat, smoother=bs)
res = gam.fit()
print(res.summary())
Generalized Linear Model Regression Results
==============================================================================
Dep. Variable: wage No. Observations: 3000
Model: GLMGam Df Residuals: 2981
Model Family: Gaussian Df Model: 18.00
Link Function: Identity Scale: 1230.5
Method: PIRLS Log-Likelihood: -14920.
Date: Sun, 14 Dec 2025 Deviance: 3.6680e+06
Time: 09:20:03 Pearson chi2: 3.67e+06
No. Iterations: 3 Pseudo R-squ. (CS): 0.3436
Covariance Type: nonrobust
================================================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------------------------
education_2. HS Grad 16.2973 2.337 6.975 0.000 11.718 20.877
education_3. Some College 27.8392 2.505 11.114 0.000 22.930 32.749
education_4. College Grad 41.0763 2.533 16.219 0.000 36.113 46.040
education_5. Advanced Degree 63.9348 2.792 22.897 0.000 58.462 69.408
jobclass_2. Information 4.8618 1.355 3.589 0.000 2.206 7.517
maritl_2. Married 13.3632 1.875 7.128 0.000 9.689 17.038
maritl_3. Widowed -0.2441 8.279 -0.029 0.976 -16.470 15.982
maritl_4. Divorced -0.1040 3.039 -0.034 0.973 -6.059 5.851
maritl_5. Separated 7.0577 5.046 1.399 0.162 -2.832 16.947
age_s0 63.8878 5.262 12.142 0.000 53.575 74.200
age_s1 63.1018 4.154 15.191 0.000 54.960 71.243
age_s2 74.8020 5.531 13.524 0.000 63.961 85.643
age_s3 56.5913 8.534 6.631 0.000 39.865 73.318
age_s4 47.4594 12.372 3.836 0.000 23.211 71.708
year_s0 4.3025 4.127 1.043 0.297 -3.786 12.391
year_s1 7.1829 4.559 1.575 0.115 -1.753 16.119
year_s2 10.0632 4.781 2.105 0.035 0.692 19.435
year_s3 7.1947 4.284 1.679 0.093 -1.202 15.591
year_s4 10.7707 2.344 4.595 0.000 6.176 15.365
================================================================================================
Exercise 8: Trees#
Inspect the data
How many features are there and what are they?
What is the target?
Split the data into a train and test set, and make sure the classes are equally distributed (
stratify=y)Fit the DecisionTreeClassifier(max_depth=3) and report train vs. test accuracy.
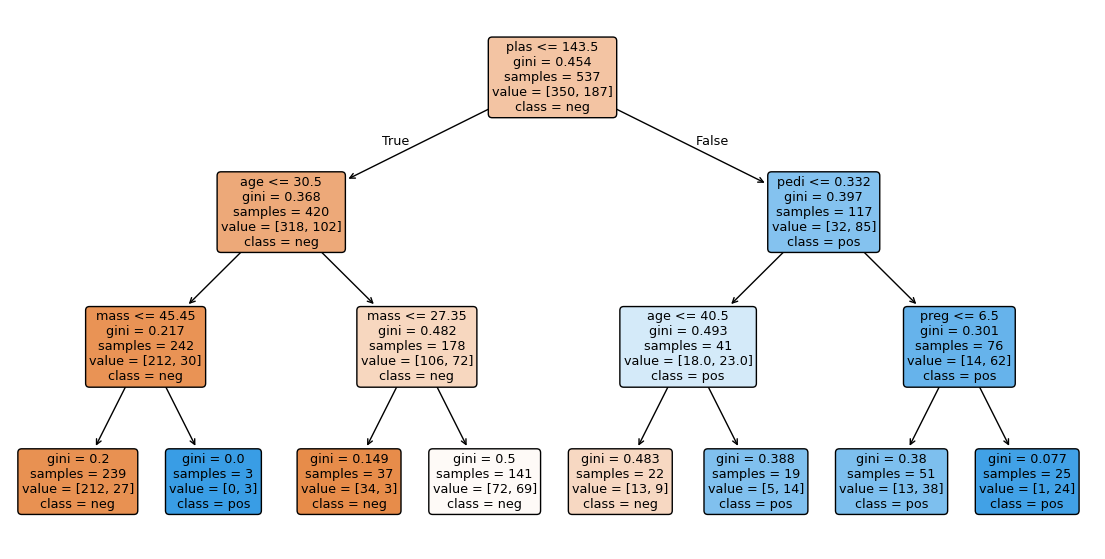
Tree inspection (discuss in group)
After fitting the model, the tree will be plotted automatically
What is the very first split (feature name and threshold)?
Which leaf nodes are pure, and which have mixed classes?
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# 1) Load and inspect data
diab = fetch_openml("diabetes", version=1, as_frame=True)
X = diab.data
y = diab.target
print(X.head(), "\n")
print(y.head())
# 2) Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, stratify=y, random_state=0)
# 3) Fit tree
clf = DecisionTreeClassifier(max_depth=3, random_state=0)
clf.fit(X_train, y_train)
print("\nTrain accuracy:", accuracy_score(y_train, clf.predict(X_train)))
print("Test accuracy: ", accuracy_score(y_test, clf.predict(X_test)))
# 5) Plot tree
plt.figure(figsize=(14,7))
plot_tree(clf, feature_names=X.columns, class_names=["neg","pos"], filled=True, rounded=True);
preg plas pres skin insu mass pedi age
0 6 148 72 35 0 33.6 0.627 50
1 1 85 66 29 0 26.6 0.351 31
2 8 183 64 0 0 23.3 0.672 32
3 1 89 66 23 94 28.1 0.167 21
4 0 137 40 35 168 43.1 2.288 33
0 tested_positive
1 tested_negative
2 tested_positive
3 tested_negative
4 tested_positive
Name: class, dtype: category
Categories (2, object): ['tested_negative', 'tested_positive']
Train accuracy: 0.7635009310986964
Test accuracy: 0.7445887445887446
See if you can improve the classification performance with a random forest classifier and hyperparameter tuning.
Set up the clasifier + a parameter grid for grid search with 5-fold CV. For example, you can usee:
n_estimators: 50, 100, 200
max_depth: None, 10, 20
min_samples_split: 2, 5, 10
max_features: “sqrt”, “log2”, 0.5
Fit the model with the grid search
Print the best hyperparameters
Evaluate the best model on the test set
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score, classification_report
# 1) Set up Random Forest + parameter grid
rf = RandomForestClassifier(random_state=0)
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [None, 10, 20],
'min_samples_split': [2, 5, 10],
'max_features': ['sqrt', 'log2', 0.5]
}
# 2) Fit on training data
grid = GridSearchCV(rf, param_grid=param_grid, cv=5, scoring='accuracy', verbose=1)
grid.fit(X_train, y_train)
# 3) Print best hyperparameters
print("Best parameters:", grid.best_params_)
print(f"CV accuracy: {grid.best_score_:.3f}")
# 4) Evaluate on the held‐out test set
best_rf = grid.best_estimator_
y_pred = best_rf.predict(X_test)
print(f"\nTest accuracy: {accuracy_score(y_test, y_pred):.3f}\n")
print("Classification Report:")
print(classification_report(y_test, y_pred, target_names=['neg','pos']))
Fitting 5 folds for each of 81 candidates, totalling 405 fits
Best parameters: {'max_depth': 10, 'max_features': 'sqrt', 'min_samples_split': 2, 'n_estimators': 50}
CV accuracy: 0.773
Test accuracy: 0.788
Classification Report:
precision recall f1-score support
neg 0.83 0.85 0.84 150
pos 0.71 0.67 0.69 81
accuracy 0.79 231
macro avg 0.77 0.76 0.76 231
weighted avg 0.79 0.79 0.79 231
Exercise 9: Gradient Boosting#
Your goal is to manually implement a gradient boosting algorithm and compare it with scikit-learn’s GradientBoostingRegressor. You should complete this exercise without any new libraries.
Complete the
custom_gb_mse()andpredict_gb()functionsStart with constant prediction equal to the mean of y
Compute residuals
Fit weak learners to residuals
Update the model using a learning rate
Compare your custom implementation with sklearn
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import GradientBoostingRegressor
rng = np.random.RandomState(1)
# Data: sin curve + noise
X = np.linspace(0, 6, 160).reshape(-1, 1)
y = np.sin(X).ravel() + rng.normal(scale=0.25, size=len(X))
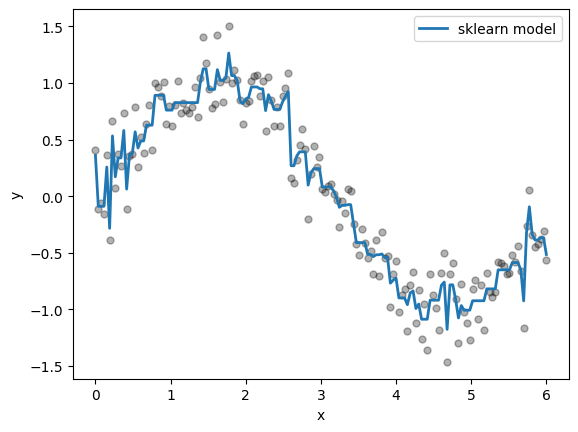
# Sklearn model
gb_sklearn = GradientBoostingRegressor(n_estimators=200, learning_rate=0.1, max_depth=2, random_state=0)
gb_sklearn.fit(X, y)
y_pred_sklearn = gb_sklearn.predict(X)
# Initial plot
fig, ax = plt.subplots()
ax.scatter(X, y, s=25, alpha=0.3, color="black")
ax.plot(X, y_pred_sklearn, label="sklearn model", linewidth=2)
ax.set(xlabel="x", ylabel="y")
ax.legend();
from sklearn.tree import DecisionTreeRegressor
def custom_gb_mse(X, y, M=50, max_depth=2, learning_rate=0.1, random_state=0):
rng = np.random.RandomState(random_state)
# Initialise the model with a constant predictor.
f0 = y.mean()
F = np.full_like(y, fill_value=f0, dtype=float)
learners = []
for _ in range(M):
# Compute the pseudo-residuals for the squared error loss.
# Hint: This requires you to calculate the negative gradient of the loss with respect to the current prediction F.
r = y - F
# Fit a weak learner (shallow regression tree) to the residuals. Each tree learns how to correct the current model's mistakes.
tree = DecisionTreeRegressor(max_depth=max_depth, random_state=rng.randint(0, 10_000))
tree.fit(X, r)
# Update the current model by adding the new tree's predictions, scaled by the learning rate.
F = F + learning_rate * tree.predict(X)
learners.append(tree)
return f0, learners
def predict_gb(X_new, f0, learners, learning_rate):
# Compute predictions of the full boosted model. Start from the constant baseline f0 and add the contributions.
pred = np.full(X_new.shape[0], f0, dtype=float)
for tree in learners:
pred += learning_rate * tree.predict(X_new)
return pred
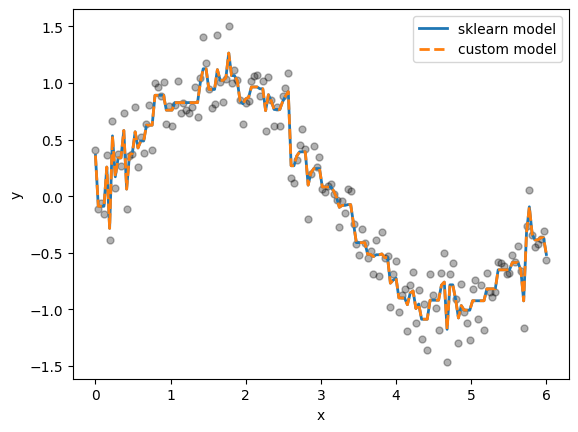
# Train the model
f0, learners = custom_gb_mse(X, y, M=200, max_depth=2, learning_rate=0.1, random_state=0)
y_pred_custom = predict_gb(X, f0, learners, learning_rate=0.1)
# Plot comparison with sklearn
fig, ax = plt.subplots()
ax.scatter(X, y, s=25, alpha=0.3, color="black")
ax.plot(X, y_pred_sklearn, label="sklearn model", lw=2)
ax.plot(X, y_pred_custom, label="custom model", lw=2, ls="--")
ax.set(xlabel="x", ylabel="y")
ax.legend();
Exercise 10: SVMs#
For the SVM exercise we will use the fmri dataset from seaborn, which contains measurements of brain activity (signal) in two brain regions (frontal and parietal) under two event types (stim vs. cue).
import seaborn as sns
df = sns.load_dataset("fmri")
df
| subject | timepoint | event | region | signal | |
|---|---|---|---|---|---|
| 0 | s13 | 18 | stim | parietal | -0.017552 |
| 1 | s5 | 14 | stim | parietal | -0.080883 |
| 2 | s12 | 18 | stim | parietal | -0.081033 |
| 3 | s11 | 18 | stim | parietal | -0.046134 |
| 4 | s10 | 18 | stim | parietal | -0.037970 |
| ... | ... | ... | ... | ... | ... |
| 1059 | s0 | 8 | cue | frontal | 0.018165 |
| 1060 | s13 | 7 | cue | frontal | -0.029130 |
| 1061 | s12 | 7 | cue | frontal | -0.004939 |
| 1062 | s11 | 7 | cue | frontal | -0.025367 |
| 1063 | s0 | 0 | cue | parietal | -0.006899 |
1064 rows × 5 columns
We will try to answer a very simple research question:
Can we distinguish between
cueandstimevents based on the fMRI signal in theparietalandfrontalbrain regions?
To do this, we need to turn the long‐format data into a classic “feature matrix” (one row = one sample, two columns = our two brain‐region signals) plus a corresponding label vector (cue/stim):
df_wide = df.pivot_table(
index=["subject","timepoint","event"],
columns="region",
values="signal"
).reset_index()
df_wide.columns.name = None
X = df_wide[["frontal","parietal"]]
y = df_wide["event"].map({"cue":0,"stim":1})
print("\nFeatures:")
print(X.head())
print("\nTarget:")
print(y.head())
Features:
frontal parietal
0 0.007766 -0.006899
1 -0.021452 -0.039327
2 0.016440 0.000300
3 -0.021054 -0.035735
4 0.024296 0.033220
Target:
0 0
1 1
2 0
3 1
4 0
Name: event, dtype: int64
With the features and target in the correct form, please perform the following tasks:
Split the data into a train and test set
Scale the predictors to mean 0 and std 1
Fit a linear as well as a rbf SVC and discuss the classification reports
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import classification_report
# 1. Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.3, stratify=y, random_state=42)
# 2. Scale the features after splitting (important to avoid data leakage)
scaler = StandardScaler()
X_train_sc = scaler.fit_transform(X_train)
X_test_sc = scaler.transform(X_test)
# 3. Fit the SVC models and compare the classification reports
clf_lin = SVC(kernel="linear", random_state=42)
clf_lin.fit(X_train_sc, y_train)
y_pred_lin = clf_lin.predict(X_test_sc)
print("Linear SVC\n", classification_report(y_test, y_pred_lin))
clf_rbf = SVC(kernel="rbf", random_state=42)
clf_rbf.fit(X_train_sc, y_train)
y_pred_rbf = clf_rbf.predict(X_test_sc)
print("RBF SVC\n", classification_report(y_test, y_pred_rbf))
Linear SVC
precision recall f1-score support
0 0.55 0.99 0.71 80
1 0.94 0.20 0.33 80
accuracy 0.59 160
macro avg 0.75 0.59 0.52 160
weighted avg 0.75 0.59 0.52 160
RBF SVC
precision recall f1-score support
0 0.67 0.85 0.75 80
1 0.79 0.57 0.67 80
accuracy 0.71 160
macro avg 0.73 0.71 0.71 160
weighted avg 0.73 0.71 0.71 160
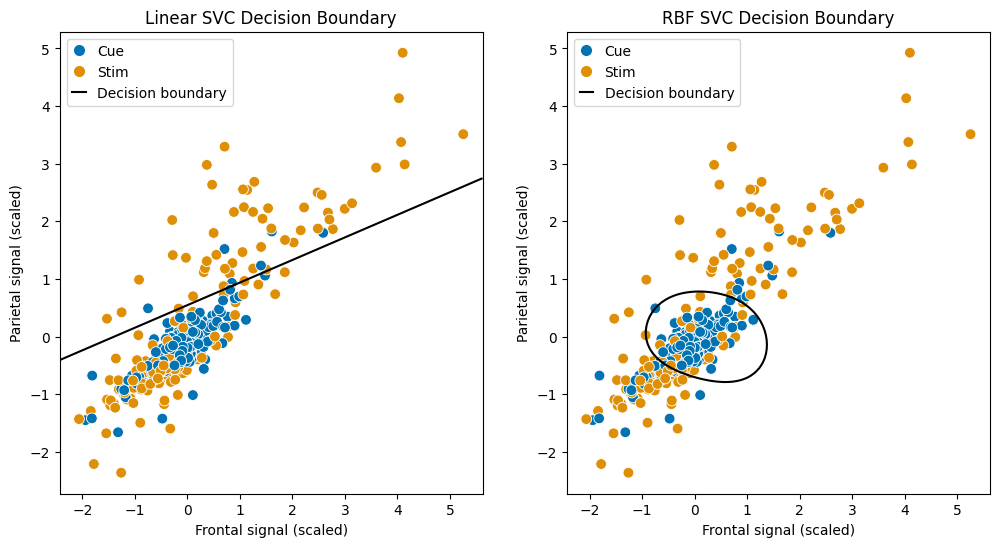
After fitting both models, you can run the code chunk below to plot the decision boundary:
import matplotlib.pyplot as plt
from matplotlib.lines import Line2D
def plot_svc_decision_function(model, ax=None):
"""Plot the decision boundary for a trained 2D SVC model."""
# Set up grid
xlim = ax.get_xlim()
ylim = ax.get_ylim()
xx, yy = np.meshgrid(np.linspace(*xlim, 100), np.linspace(*ylim, 100))
grid = np.c_[xx.ravel(), yy.ravel()]
decision_values = model.decision_function(grid).reshape(xx.shape)
ax.contour(xx, yy, decision_values, levels=[0], linestyles=['-'], colors='k')
# Plot
fig, ax = plt.subplots(1,2, figsize=(12, 6))
legend_elements = [
Line2D([0], [0], marker='o', linestyle='None', markersize=8, label='Cue', markerfacecolor="#0173B2", markeredgecolor='None'),
Line2D([0], [0], marker='o', linestyle='None', markersize=8, label='Stim', markerfacecolor="#DE8F05", markeredgecolor='None'),
Line2D([0], [0], color='k', linestyle='-', label='Decision boundary')]
# Linear SVC
sns.scatterplot(x = X_train_sc[:, 0], y = X_train_sc[:, 1], hue = y_train.map({0:"cue",1:"stim"}), palette = ["#0173B2", "#DE8F05"], s = 60, ax = ax[0], legend=None)
ax[0].set(xlabel = "Frontal signal (scaled)", ylabel = "Parietal signal (scaled)", title = "Linear SVC Decision Boundary")
plot_svc_decision_function(clf_lin, ax=ax[0])
ax[0].legend(handles=legend_elements, loc="upper left", handlelength=1)
# RBF SVC
sns.scatterplot(x = X_train_sc[:, 0], y = X_train_sc[:, 1], hue = y_train.map({0:"cue",1:"stim"}), palette = ["#0173B2", "#DE8F05"], s = 60, ax = ax[1], legend=None)
ax[1].set(xlabel = "Frontal signal (scaled)", ylabel = "Parietal signal (scaled)", title = "RBF SVC Decision Boundary")
plot_svc_decision_function(clf_rbf, ax=ax[1])
ax[1].legend(handles=legend_elements, loc="upper left", handlelength=1);
Training a Support Vector Classifier (SVC) on more complex datasets often requires a systematic hyperparameter search to identify optimal model settings.
Implement a grid search that explores multiple kernels and their corresponding hyperparameters using the following configuration:
Kernels:
rbf,linearC:
np.logspace(-2, 2, 10)gamma:
np.logspace(-3, 1, 10)(forrbf)
Further use:
Cross-validation: 5-fold
Scoring metric: accuracy
Note: Usually you would use a finer grid, but we keep it simpler for the sake of the exercise.
After fitting the model:
Print the optimal hyperparameters
Print the best cross-validation accuracy
Print the test accuracy
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
import numpy as np
param_grid = [
# RBF kernel
{
"kernel": ["rbf"],
"C": np.logspace(-2, 2, 10),
"gamma": np.logspace(-3, 1, 10)
},
# Linear kernel
{
"kernel": ["linear"],
"C": np.logspace(-2, 2, 10)
},
]
grid = GridSearchCV(
SVC(),
param_grid,
cv=5,
scoring="accuracy",
n_jobs=-1
)
grid.fit(X_train_sc, y_train)
print("Best params:", grid.best_params_)
print("CV accuracy:", grid.best_score_)
print("Test accuracy:", grid.score(X_test_sc, y_test))
Best params: {'C': np.float64(0.21544346900318834), 'gamma': np.float64(3.593813663804626), 'kernel': 'rbf'}
CV accuracy: 0.7605765765765765
Test accuracy: 0.74375