ML Basics Exercises#
Exercise 1: Psy111 Recap#
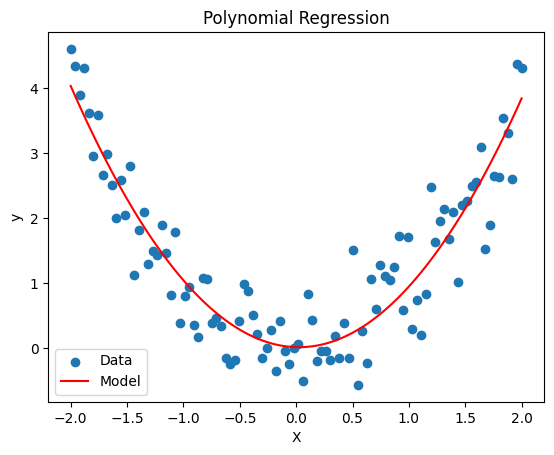
Remember the materials from last semester. Can you implement regression models using statsmodels as well as the sklearn package? Which degree of polynomial will be most suited for the synthetic data?
Please plot the result
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
# Generate synthetic data
n_samples = 100
X = np.linspace(-2, 2, n_samples).reshape(-1, 1)
y = X**2 + np.random.normal(scale=0.5, size=X.shape)
# TODO: Statsmodels
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X)
model = sm.OLS(y, X_poly)
fit = model.fit()
print(fit.summary())
# TODO: Scikit-learn
X_poly = poly.fit_transform(X)
model = LinearRegression()
model.fit(X_poly, y)
# TODO: Plot the predictions
fig, ax = plt.subplots()
ax.scatter(X, y, label='Data')
ax.plot(X, model.predict(X_poly), label='Model', color='red')
ax.set(xlabel='X', ylabel='y', title='Polynomial Regression')
ax.legend();
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.850
Model: OLS Adj. R-squared: 0.847
Method: Least Squares F-statistic: 275.2
Date: Mon, 07 Apr 2025 Prob (F-statistic): 1.04e-40
Time: 09:52:53 Log-Likelihood: -72.907
No. Observations: 100 AIC: 151.8
Df Residuals: 97 BIC: 159.6
Df Model: 2
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 0.0127 0.076 0.166 0.868 -0.139 0.164
x1 -0.0479 0.044 -1.097 0.275 -0.135 0.039
x2 0.9812 0.042 23.434 0.000 0.898 1.064
==============================================================================
Omnibus: 0.536 Durbin-Watson: 1.975
Prob(Omnibus): 0.765 Jarque-Bera (JB): 0.656
Skew: -0.009 Prob(JB): 0.720
Kurtosis: 2.604 Cond. No. 3.25
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Exercise 2: Bias-variance Tradeoff#
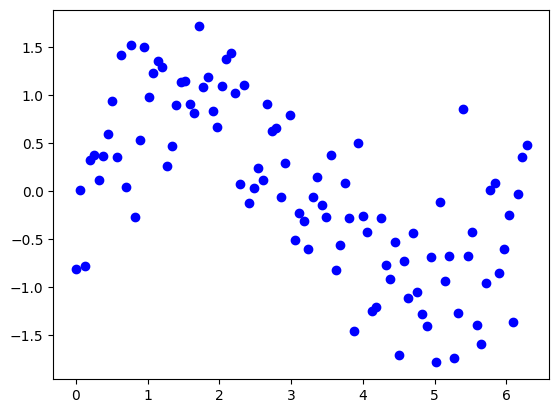
To get a better understanding about the bias-variance tradeoff, we will fit polynomial regression models to synthetic data from a known function \(y=sin(x)\).
Please perform the following tasks:
Visualize the data. Which model do you think would be optimal?
Split the data into a training set (70%) and testing set (30%)
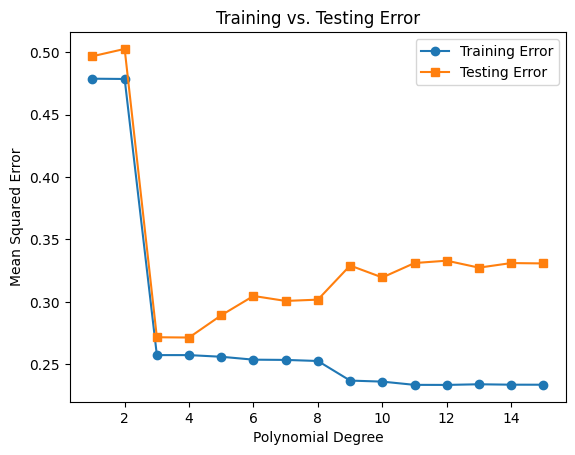
Fit polynomial regression models for degrees 1 to 15
Plot the training and testing errors against polynomial degree
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
# Generate synthetic data
np.random.seed(55)
n_samples = 100
X = np.linspace(0, 2*np.pi, n_samples).reshape(-1, 1) # Reshape for sklearn
y = np.sin(X) + np.random.normal(scale=0.5, size=X.shape)
# 1. TODO: Visualize the data
plt.scatter(X, y, label='Data', color='blue')
# 2. TODO: Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 3. TODO: Fit polynomial regression models for degrees 1 to 15
degrees = range(1, 16)
train_errors = []
test_errors = []
for degree in degrees:
# Transform the features into polynomial features
poly = PolynomialFeatures(degree=degree)
X_train_poly = poly.fit_transform(X_train)
X_test_poly = poly.transform(X_test)
# Fit a linear regression model on the polynomial features
model = LinearRegression()
model.fit(X_train_poly, y_train)
# Predict on both training and testing sets
y_train_pred = model.predict(X_train_poly)
y_test_pred = model.predict(X_test_poly)
# Calculate mean squared errors
train_errors.append(mean_squared_error(y_train, y_train_pred))
test_errors.append(mean_squared_error(y_test, y_test_pred))
# 4. Plot the training and testing errors against polynomial degree
fig, ax = plt.subplots()
ax.plot(degrees, train_errors, marker='o', label='Training Error')
ax.plot(degrees, test_errors, marker='s', label='Testing Error')
ax.set(xlabel="Polynomial Degree", ylabel="Mean Squared Error", title="Training vs. Testing Error")
ax.legend();
Exercise 3: Resampling Methods#
The dataset we are using for the exercise is the California Housing Dataset. It contains 20640 samples and 8 features. In this dataset, we have information regarding the demography (income, population, house occupancy) in the districts, the location of the districts (latitude, longitude), and general information regarding the house in the districts (number of rooms, number of bedrooms, age of the house). Since these statistics are at the granularity of the district, they corresponds to averages or medians.
Familiarize yourself with the dataset by exploring the documentation and looking at the data. What are the features and target?
from sklearn.datasets import fetch_california_housing
data = fetch_california_housing(as_frame=True)
df = data.frame
df.head()
| MedInc | HouseAge | AveRooms | AveBedrms | Population | AveOccup | Latitude | Longitude | MedHouseVal | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 8.3252 | 41.0 | 6.984127 | 1.023810 | 322.0 | 2.555556 | 37.88 | -122.23 | 4.526 |
| 1 | 8.3014 | 21.0 | 6.238137 | 0.971880 | 2401.0 | 2.109842 | 37.86 | -122.22 | 3.585 |
| 2 | 7.2574 | 52.0 | 8.288136 | 1.073446 | 496.0 | 2.802260 | 37.85 | -122.24 | 3.521 |
| 3 | 5.6431 | 52.0 | 5.817352 | 1.073059 | 558.0 | 2.547945 | 37.85 | -122.25 | 3.413 |
| 4 | 3.8462 | 52.0 | 6.281853 | 1.081081 | 565.0 | 2.181467 | 37.85 | -122.25 | 3.422 |
Let’s have a quick look at the distribution of these features by plotting their histograms.
df.hist(figsize=(12, 10), bins=30, edgecolor="black");
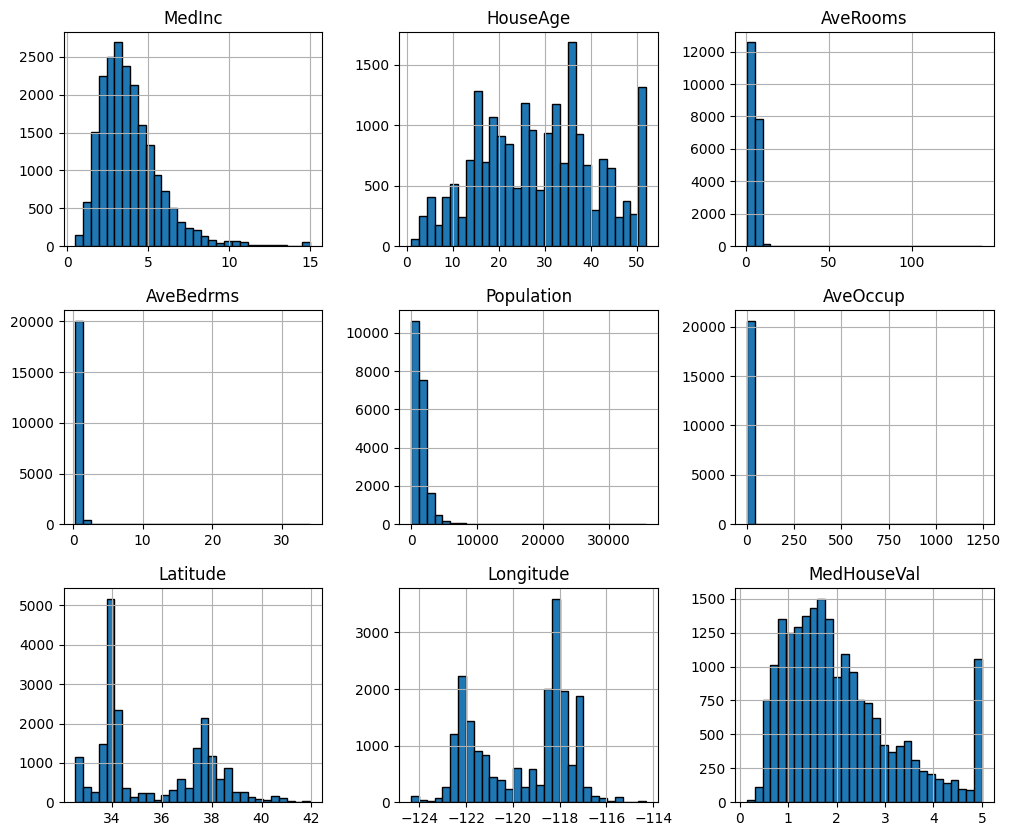
Prepare the data for cross validation. This will require you to have a variable (e.g.
X) for the features and a variable for the target (e.g.y).Set up a k-fold cross validation for a linear regression
Choose an appropriate k
Define the model
Perform cross validation
Use the mean squared error (MSE) to assess model performance
Hints:
For 1: You can achieve this by e.g. creating them from the DataFrame, or by using the
return_X_yparameter on thefetch_california_housing()functionFor 2: You can use the
LinearRegession()model from sklearn. You can further evaluate the model and specify the (negative) MSE as a performance measure incross_val_score()
# TODO: Prepare data
X, y = fetch_california_housing(return_X_y=True)
from sklearn.model_selection import KFold
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_score
# TODO: Implement CV
k_fold = KFold(n_splits=5)
model = LinearRegression()
neg_mse = cross_val_score(model, X, y, cv=k_fold, scoring='neg_mean_squared_error')
mse = -neg_mse
print(f"Average MSE: {mse.mean()}")
print(f"MSE for each fold: {mse}")
Average MSE: 0.5582901717686809
MSE for each fold: [0.48485857 0.62249739 0.64621047 0.5431996 0.49468484]
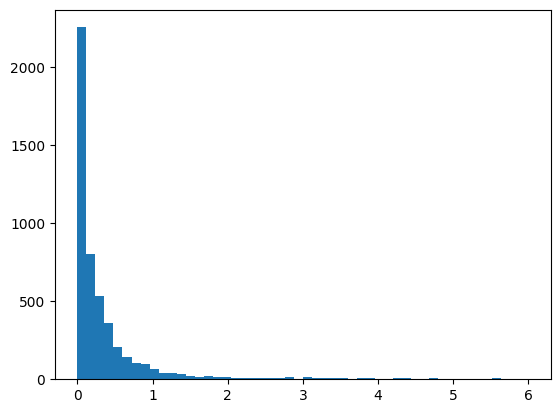
Exercise 4: LOOCV#
Use LOOCV and compare the average MSE
Get the minimum and maximum MSE value. Discuss the range!
Plot the MSE values in a histogram (the x-range should be from 0 to 6)
Calculate the median MSE and discuss if it might be a more appropriate measure than the mean
Hints
As we have 20640 observations this will probably take more than a minute to calculate. Feel free to subset the number of observations to e.g. 5000.
# TODO: Implement LOOCV
import numpy as np
from matplotlib import pyplot as plt
from sklearn.model_selection import LeaveOneOut
loocv = LeaveOneOut()
model = LinearRegression()
# Subset the data to speed up the process
X = X[:5000,:]
y = y[:5000]
# Perform LOOCV
neg_mse = cross_val_score(model, X, y, cv=loocv, scoring='neg_mean_squared_error')
mse = -neg_mse
# Get MSE metrics
print(f"Average MSE: {mse.mean()}")
print(f"Minimum MSE: {mse.min()}")
print(f"Maximum MSE: {mse.max()}")
print(f"Median MSE: {np.median(mse)}")
# Plot MSE
plt.hist(mse, bins=50, range=(0,6));
Average MSE: 4.52148803454314
Minimum MSE: 4.8924903912868155e-08
Maximum MSE: 20152.477041272956
Median MSE: 0.14930186919081195